
Part 2: Créer votre pipeline SQL avec Dataform UI & BigQuery










Introduction
Dataform, nouvellement acquis par Google, est un outil de transformation des données pour les Data warehouse cloud comme BigQuery, Redshift et Azure Data warehouse. Après avoir introduit l’outil et présenté un premier use case basé le client Dataform CLI, nous allons désormais étudier l’interface web de cet outil en se basant sur les données publiques issues de stack-overflow. En effet, la vraie expérience utilisateur vient avec l’utilisation de l’interface web Dataform.
Afin de tester les instructions de cet article, vous aurez besoin d’un référentiel Git. C’est ce qui vous permettra de collaborer avec vos coéquipiers au sein d’un projet de transformation des données.
Pour cela, vous pouvez récupérer le projet Dataform de notre cas d’usage à partir de mon référentiel Git: https://github.com/zaimielm1/stack_overflow_example_dataform.git .
D’abord, connectez vous à https://www.dataform.co , et cliquez sur Import project ou example. Ensuite, renseignez le référentiel Git indiqué ci-dessus et spécifiez fork pour l’importer dans votre espace de travail.
Dans les paramètres Dataform, indiquez l’identifiant (id) de votre projet GCP. Vous devez également télécharger le fichier JSON de compte de service pour BigQuery (pour plus d’info sur la clé de service, consultez la page: https://cloud.google.com/iam/docs/creating-managing-service-account-keys?hl=fr).
Note:Cet exemple de projet Dataform est issu du Git Officiel de Dataform. Vous pouvez trouver d’autres exemples dans le même espace https://github.com/dataform-co.
1. Créer un pipeline SQL pour générer un rapport
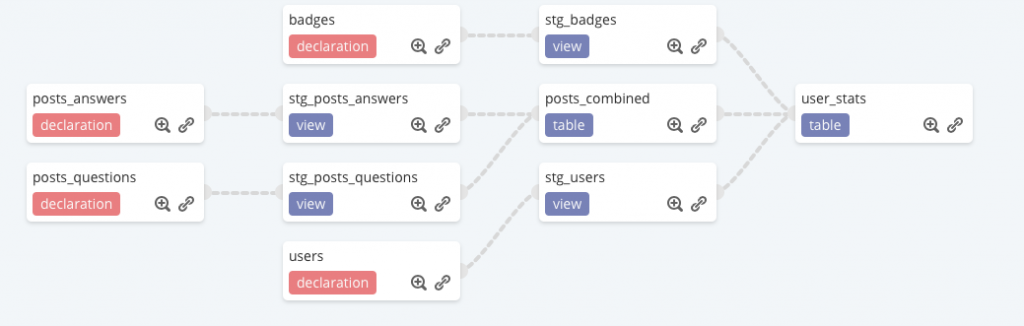
Construisons le flux de données ci-dessous pour créer un rapport statistique sur les questions posés par les utilisateurs de stack-overflow depuis le 01-02-2021.
2. Préparer les données des utilisateurs stack-overflow
Dataform génère des fichiers de type .SQLX c’est une version évoluée du SQL qui permet de gérer à la fois le type du traitement à réaliser (déclaration d’une source de données, création de vues, tables ou assertions), les transformations sql à réaliser et la documentation. Ces fichiers doivent être créés dans le répertoire définitions.
Afin d’organiser notre projet, créons les sous-dossiers suivants :
Pour cela, cliquer sur les trois points à côté de definitions et choisissez new Folder.
2.1 Déclarer les sources de données
Cliquez sur les trois points à côté de source et créer les quatre sources de données ci-dessous. Notez que ce sont des tables de type declaration .
users.sqlx : table source des utilisateurs
config {
type: "declaration",
database: "bigquery-public-data",
schema: "stackoverflow",
name: "users",
description: "raw users table"
}posts_questions: table source des questions
config {
type: "declaration",
database: "bigquery-public-data",
schema: "stackoverflow",
name: "posts_questions",
description: "raw posts_questions table"
}posts_answers: table source des réponses
config {
type: "declaration",
database: "bigquery-public-data",
schema: "stackoverflow",
name: "posts_answers",
description: "raw posts_answers table"
}badges: table source des badges
config {
type: "declaration",
database: "bigquery-public-data",
schema: "stackoverflow",
name: "badges",
description: "raw badges table"
}2.2 Créer les vues et tables intermédiaires
Cliquez sur les trois points à côté de staging et créer les quatre fichiers .sqlx ci-dessous :
stg_users: version « nettoyée » de la table stackoverflow.users
config {
type: "view",
schema: "staging",
description: "Cleaned version of stackoverflow.users table"
}
select
id as user_id,
age,
creation_date,
round(timestamp_diff(current_timestamp(), creation_date, day)/365) as user_tenure
from
${ref("users")}
limit 10stg_posts_questions: version « nettoyée » de la table stackoverflow.posts_questions
config {
type: "view",
schema: "staging",
description: "Cleaned version of stackoverflow.posts_questions"
}
select
id as post_id,
creation_date as created_at,
'question' as type,
title,
body,
owner_user_id,
parent_id
from
${ref("posts_questions")}
where
-- limit to recent data for the purposes of this demo project
creation_date >= timestamp("2021-02-01")
limit 10stg_posts_answers: version « nettoyée de la table stackoverflow.posts_answers.
config {
type: "view",
schema: "staging",
description: "Cleaned version of stackoverflow.posts_answers"
}
select
id as post_id,
creation_date as created_at,
'answer' as type,
title,
body,
owner_user_id,
cast(parent_id as string) as parent_id
from
${ref("posts_answers")}
where
-- limit to recent data for the purposes of this demo project
creation_date >= timestamp("2021-02-01")
limit 10stg_badges: version « nettoyée de la table stackoverflow.badges
config {
type: "view",
schema: "staging",
description: "Cleaned version of stackoverflow.badges"
}
select
id as badge_id,
name as badge_name,
date as award_timestamp,
user_id
from
${ref("badges")}
limit 10Notez que le menu de droite compile la requête. Il vous permet également de prévisualiser les résultats, de créer la vue ou la table, etc. Une fois votre requête est correcte, supprimez la clause LIMIT
2.3 Créer le rapport « user_stats »
Créez d’abord le fichier posts_combined.sqlx dans le sous dossier reporting. Cet ensemble de données, combine à la fois les questions et les réponses des utilisateurs stack_overflow dans la même table
config {
type: "table",
schema: "reporting",
tags: ["daily"],
bigquery: {
partitionBy: "date(created_at)"
},
description: "Combine both questions and answers into a single posts_all table",
assertions: {
uniqueKey: ["post_id"]
}
}
select
post_id,
created_at,
type,
title,
body,
owner_user_id,
parent_id
from
${ref("stg_posts_answers")}
union all
select
post_id,
created_at,
type,
title,
body,
owner_user_id,
parent_id
from
${ref("stg_posts_questions")}
limit 10Enfin créez le rapport user_stats.sqlx dans le sous dossier reporting.
config {
type: "table",
schema: "reporting",
tags: ["daily"],
description: "Create a summary table for all users including statistics on questions, answeers and badges received.",
assertions: {
uniqueKey: ["user_id"],
rowConditions: ["badge_count >= 0"]
}
}
select
stg_users.user_id,
stg_users.age,
stg_users.creation_date,
stg_users.user_tenure,
count(distinct stg_badges.badge_id) as badge_count,
count(distinct posts_all.post_id) as questions_and_answer_count,
count(distinct if(type="question", posts_all.post_id, null)) as question_count,
count(distinct if(type="answer", posts_all.post_id, null)) as answer_count,
max(stg_badges.award_timestamp) as last_badge_received_at,
max(posts_all.created_at) as last_posted_at,
max(if(type="question", posts_all.created_at, null)) as last_question_posted_at,
max(if(type="answer", posts_all.created_at, null)) as last_answer_posted_at
from
${ref("stg_users")} as stg_users
left join ${ref("stg_badges")} as stg_badges
on stg_users.user_id = stg_badges.user_id
left join ${ref("posts_combined")} as posts_all
on stg_users.user_id = posts_all.owner_user_id
group by
1,2,3,4
limit 10Ce script crée une synthèse de l’ensemble des utilisateurs, incluant les statistiques liées aux questions, aux réponses et aux badges reçus.
A ce stade du projet, nous avons déclaré des sources de données, préparé les données et créé un rapport statistique sur les utilisateurs de stack_overflow. Nous avons également assuré le data lineage et mettant en place des jointures via l’instruction ${ref("nom_source_données")}. De cette manière, Dataform vous permet de créer les dépendances afin de vous assurer que les données issues de stackoverflow existent (rappelez-vous que nous voulions que notre rapport soit une table).
3. Exécuter votre projet
Avant d’exécuter le projet, cliquer sur dependency tree (accessible via le menu en haut à gauche de l’interface web Dataform), pour visualiser comment votre projet est organisé.
La table user_stats ressemble à :
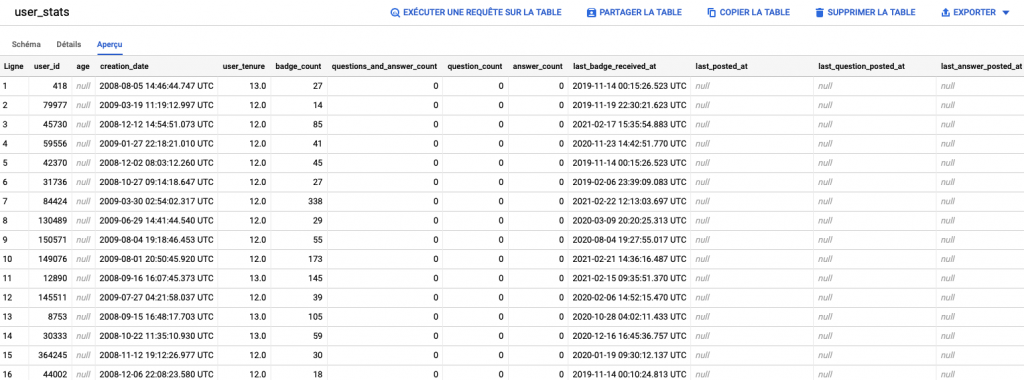
Vous pouvez désormais utiliser cette table comme une entrée dans votre outil BI.
Vous pouvez également cliquer sur create schedule pour planifier l’exécution de l’ensemble du processus. Il est également possible d’enrichir votre Data warehouse en s’inspirant du même processus.
Conclusion
J’espère que cet article vous sera utile pour bien commencer avec Dataform. En effet, via cet article ainsi que le précédent (https://elmehdizaimi.com/part-1-creer-votre-pipeline-sql-avec-dataform-cli-big-query), j’ai essayé d’exposer des notions de base pour pouvoir appréhender l’outil Dataform en utilisant le langage SQL et le Data warehouse BigQuery.
Notez également, qu’il est possible d’utiliser le langage .javascript pour mettre en place des transformations complexes de vos données. De même, n’oubliez pas que Dataform se positionne comme outil de modélisation des données pour les entrepôts de données cloud comme BigQuery, Amazon Redshift et Azure Datawarehouse. De ce fait, il faudrait le considérer comme un outil intermédiaire entre votre processus de collecte des données et celui permettant de les exploiter via des outils BI par exemple.
Enfin, il est possible d’automatiser votre flux de données Dataform en mettant en place une chaîne d’intégration continue CI/CD.
Le code source de ce projet est accessible via mon référentiel Git: https://github.com/zaimielm1/stack_overflow_example_dataform.git