Part 1: Créer votre pipeline SQL avec Dataform CLI & Big Query










Introduction
De plus en plus d’utilisateurs s’orientent vers le SQL pour transformer leurs données. Cette tendance s’explique par deux raisons: (1) le SQL est facile à écrire comparé à des ETL tels que Talend, Apach Beam, etc. (2) Le faible coût du stockage et du traitement des données suite à la démocratisation des Data warehouse cloud.
Cependant, maintenir des scripts SQL, des tables, des vues, versioning, etc, peut rapidement se révéler complexe. Il vous suffit de revenir sur un projet de transformation quelques mois plus tard, pour réaliser combien il est difficile de se remettre dans le « code » et de se repérer dans les différents scripts, tables, etc.

C’est pourquoi il est important d’avoir un environnement de transformation des données, doté des meilleurs pratiques issues de l’ingénierie logicielle : documentation, versioning du code, réutilisabilité, tests unitaires, etc.
Dataform, nouvellement acquis par Google, se définit comme un OS pour les entrepôts de données cloud. Il gère nativement les point cités plus haut.
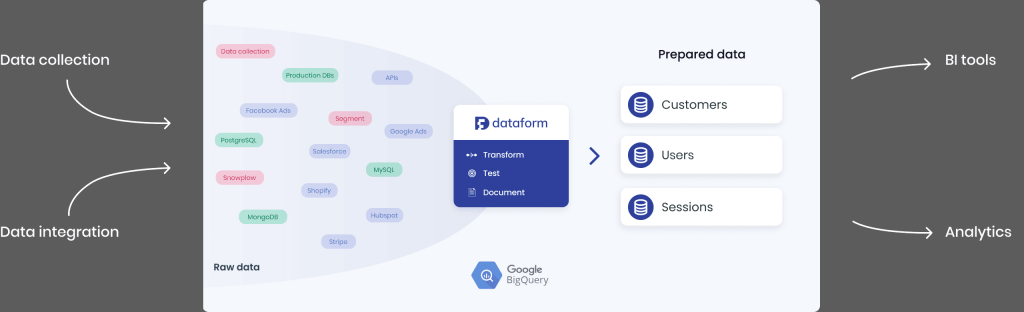
Dans cet article nous allons voir ensemble comment configurer et mettre en place votre premier projet de transformation en utilisant: Dataform/CLI, SQL & BigQuery. Par la suite, nous présenterons (dans un nouvel article) l’interface web de Dataform, afin de tirer pleinement profit de cet outil.
pré-requis
- Pour tester les instructions cités dans cet article, il faudrait avoir un accès à GCP (Google Cloud Platform). Vous pouvez bénéficier d’un crédit gratuit de 300$, valable 90 jours pour tester cette platform (voir l’article: https://cloud.google.com/free/docs/gcp-free-tier?hl=fr)
- Prendre connaissance de l’article « Introduction dataform«
1. Installer Dataform CLI
Dans GCP ouvrir CloudShell. C’est l’icône ( >_ ) en haut à droite.
npm i -g @dataform/cli2. Initialiser un projet Dataform
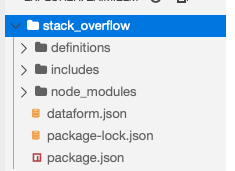
Ensuite, créer un nouveau projet Dataform. Dans cet exemple, il est nommé stack_overflow
dataform init bigquery stack_overflow \
--default-database $(gcloud config get-value project) \
--include-schedulesA ce stade, vous avez créé l’arborescence suivante:
3. configurer l’accès à BigQuery
Accédez à https://console.cloud.google.com/iam-admin/serviceaccounts et créez un compte de service. Attribuez à ce compte le rôle d’administrateur BigQuery (afin que Dataform puisse créer de nouvelles tables, etc.). Ensuite, téléchargez la clé JSON dans le projet et téléchargez le fichier sur CloudShell.
Enfin, dans CloudShell, saisissez:
cd stack_overflow
dataform init-creds bigqueryFournissez le chemin du fichier de clé JSON lorsque vous y êtes invité. Assurez-vous ensuite d’ajouter le fichier de clé à .gitignore afin de ne pas l’archiver par erreur.
4. Initier Git:
Utilisez l’éditeur CloudShell.
git init
git remote add origin stack_overflow
echo filename.json > .gitignore
git add -f .gitignore5. Définir la source Raw
Commençons par ajouter une définition pour une source nommée definitions/sources/users.sqlx.
Créer un fichier: definitions/sources/users.sqlx
config {
type: "declaration",
database: "bigquery-public-data",
schema: "stackoverflow",
name: "users",
description: "raw users table"
}En fait, ce sont les données brutes tel qu’elles existent dans bigquery-public-data.stackoverflow.users
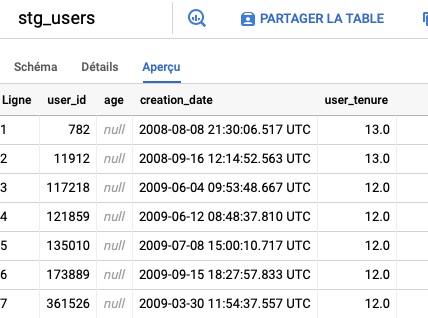
Ces données ressemblent à ceci:

Ces données doivent être préparées pour être utiles.
6. Transformer les données:
Créez un fichier nommé definitions/staging/stg_users.sqlx. Il prendra les données brutes et les formatera pour être des données users utilisables pour la source StackOverflow sous cette forme:
config {
type: "table",
schema: "staging",
description: "Cleaned version of stackoverflow.users table",
// column level documentation, defined in includes/docs.js
// columns: docs.stg_users,
}
select
id as user_id,
age,
creation_date,
round(timestamp_diff(current_timestamp(), creation_date, day)/365) as user_tenure
from
${ref("users")}Nous demandons à Dataform de créer une table pour nous (nous aurions pu également lui demander de créer une vue). En fait, nous pouvons même demander à Dataform de partitionner et de regrouper la table qu’il crée pour nous:
config {
type: "table",
bigquery: {
partitionBy: "creation_date",
clusterBy: ["id", "age"]
}
}La table va être créée à l’aide de la requête que nous venons de spécifier. Il y a deux choses essentielles à noter. Tout d’abord, la clause FROM de la table est une référence vers le nom de la table dans users.sqlx. Deuxièmement, les colonnes de la table seront documentées. La documentation est spécifiée dans includes/docs.js comme suit:
const USER_ID = {
user_id: `Unique Id of StackOverflow user`
};
const AGE = {
age: `Age of StackOverflow users`
};
const CREATION_DATE = {
creation_date: `The Date (UTC)`
};
const USER_TENURE = {
user_tenure: `Calculation of user tenure (by year)`
};
// group documentation by table
const stg_users = {
...USER_ID,
...AGE,
...CREATION_DATE,
...USER_TENURE,
};
module.exports = {
stg_users
}Fondamentalement, nous définissons les colonnes puis définissons la table (stg_users). L’idée est d’avoir des noms de colonnes uniques dans le projet et ils apparaîtront dans plusieurs vues et tables.
7. Compile et Dry Run
Essayons-le. Tout d’abord, compilez le projet en saisissant la ligne de commande:
dataform compileDataform vous indique qu’un ensemble de données staging. sera créé en tant que table.stg_users
Vous pouvez également vérifier les dépendances:
dataform run --dry-run8. Run
Exécutez-le pour créer les vues et les tables souhaitées.
dataform runEn effet, la table stg_users a été créée pour nous dans BigQuery: